you know how in school we learn matrix multiplication as taking rows from the first matrix and dotting them with columns from the second? it feels kinda weird at first, like why not just multiply element wise, or row with row, or something simpler and more "linear" like vectors? i mean, vectors we add component wise or dot them straightforwardly. why this fancy row column dance for matrices lol?
after digging deep into this (trust me, a ton of reading on history, linear algebra texts, and even some old papers), it isn't random, its super intentional.. this isn't just a convention it's the only way that lets matrices beautifully represent composition of linear transformations.
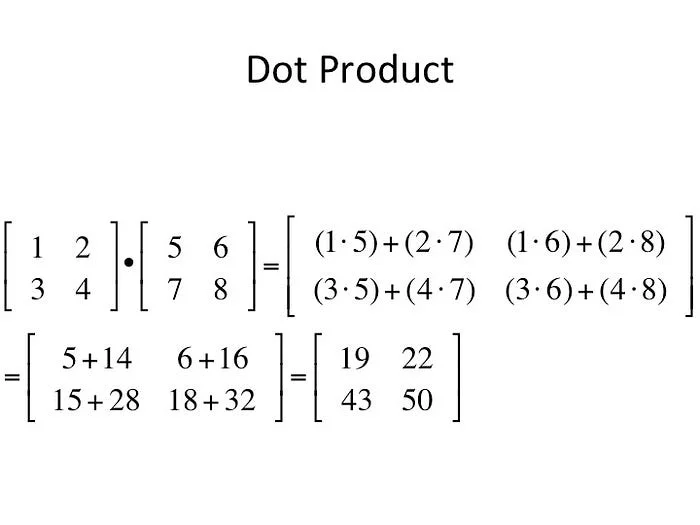
for two matrices A (m × n) and B (n × p), the product C=AB (m × p) has entries:
this corresponds to row i of A dotted with column j of B.
see how each entry is a dot product? simple, but why this way only?
Matrices Represent Linear Transformations
matrix isnt just a grid of numbers, its a way to describe a linear function that transforms vectors.
if you have a vector v (as a column vector), multiplying A with v gives the transformed vector.
the columns of A tell you where the standard basis vectors go after transformation.
now, if you have two transformations: first apply B (takes vectors from R^p to R^n), then A (R^n to R^m), the combined transformation is A dot B (composition: apply B first, then A).
to get the matrix for A dot B, you need to apply A to whatever B does.
turns out: the matrix for A dot B is exactly A B (standard multiplication)!
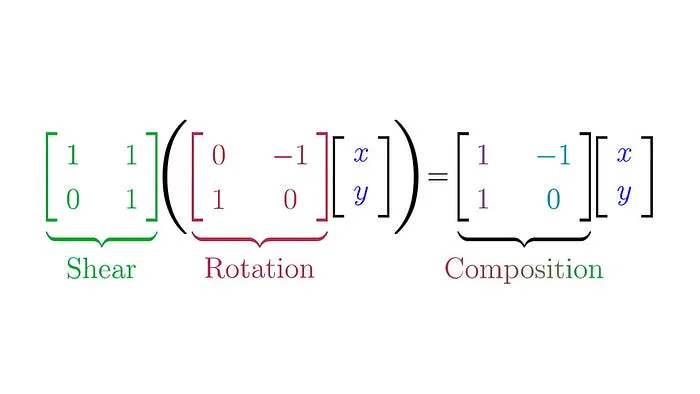
this is why row column works,, rows of A "project" onto the outputs from columns of B.
if we did column row, it would be like composing in reverse order (B A instead of A B).
Row vs Column Vectors
theres a convention debate some treat vectors as rows, some as columns.
most math uses column vectors (matrix on left: A v), leading to AB for A after B.
if row vectors (v A), it flips.
but the row column rule stays the same for composition!
Historical Bit
people used determinants and systems of equations way back (Leibniz, Cramer).
but full matrix algebra? Arthur Cayley in 1858 ("A Memoir on the Theory of Matrices").
he defined it exactly this way to handle composition of linear substitutions (transformations).
earlier hints from Binet (1812), Cauchy, but Cayley formalized it, wasn't arbitrary he needed it for chaining transformations.
Why Not Element Wise (Hadamard Product)?
super simple, O(n²) time, useful for things like scaling images pixel by pixel or neural net activations.
but it doesn't represent composition! which was our whole point.
if A and B are transformations, A ⊙ B isn't A after B or anything meaningful for chaining.
no associativity in the same way, doesn't preserve linear structure for functions.
it's called Hadamard/Schur product, great for pointwise ops, but not for linear maps.
Why Not Other Ways?
column by row? equivalent to transposing and doing standard, or reversing composition order.
Kronecker product: Blows up size (tensor stuff), for higher dim arrays.
Outer product: Single vector stuff.
none capture function composition like row column does.
Why It Feels "Non-Linear" Compared to Vectors
vectors are 1D dot product is inner product (scalar), or outer (matrix).
matrices are 2D operators on vectors.
to chain operators, you need this interleaved sum, it's the natural bilinear form.
Final Thoughts :)
the row column rule isn't complicated for fun it's elegant because it turns matrix multiplication into function composition. it unlocks all of linear algebra, eigenvalues, diagonals, changes of basis, and so much more.