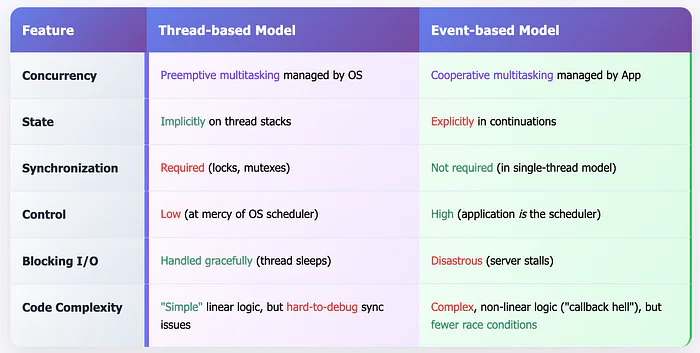
In the world of concurrent programming, threads are king. We are taught to spin up threads to handle multiple tasks at once, getting the full power of modern multi core processors. But with this power comes a great and terrible cost, the insaneeeee complexity of synchronisation. Race conditions, deadlocks, and the subtle bugs that arise from shared memory have haunted developers for decades. We write code, sprinkle it with locks, and pray that the OS scheduler is kind to us.
What if there's another way? One that powers some of the most performant systems on the internet, from high throughput web servers like Nginx to the entire Node.js ecosystem. This is the world of event-based concurrency.
This article, inspired by the foundational teachings of "Operating Systems: Three Easy Pieces," is a deep dive into this elegant paradigm.
Threads
Before we embrace a new model, we must first understand the problems with the old one. Why would we even consider building a concurrent application without threads? The reasons are twofold.
- Synchronization: As soon as you have more than one thread accessing a shared piece of data, you must protect it. This introduces synchronization primitives like mutexes, semaphores, and condition variables. Using them correctly is notoriously difficult. A forgotten lock leads to a race condition. A lock acquired in the wrong order leads to a deadlock. These issues are non deterministic, notoriously difficult to debug, and a constant source of anxiety for developers.
- Scheduling: In a multi threaded application, we create threads and hand them over to the Operating System. The OS scheduler, a complex beast designed for general purpose workloads, then decides which thread runs when. We have virtually no control. We simply hope it makes good decisions for our specific application. Sometimes, this "scheduler lottery" results in performance that is far from optimal, with threads being preempted at the worst possible moments.
This leads us to the central question, a challenge that lies at the heart of this entire discussion.
HOW TO BUILD CONCURRENT SERVERS WITHOUT THREADS?
How can we build a concurrent server that can handle many clients at once, without using threads, thereby regaining control over scheduling and sidestepping the treacherous pitfalls of traditional synchronization?
The Event Loops
The answer is surprisingly simple. It's an architectural pattern known as the event loop. Instead of multiple threads of execution, we have one. This single thread runs a simple, infinite loop.
Here is the entire philosophy captured in a few lines of pseudocode:
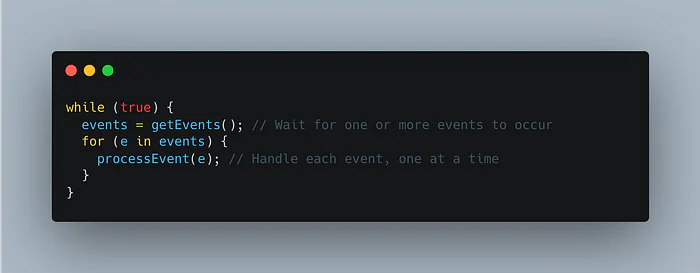
Breaking this down:-
- getEvents(): This is a blocking call that waits for something to happen. An "event" could be the arrival of a new network packet, a mouse click in a GUI, or a notification that a disk read has completed.
- processEvent(e): This is an event handler, a piece of your code that performs the work associated with a specific event.
The critical point here is that an event handler runs to completion without interruption. While processEvent(e) is executing, it is the only thing happening in your application. There are no other threads to contend with, no preemption to worry about. The event loop processes one event, then the next, then the next…, in a strictly sequential order.
This turns scheduling on its head. Instead of the OS deciding what runs next, your application is the scheduler. By deciding the order in which to process events, you have explicit, fine grained control over your application's execution.
This can be visualized as a simple, diligent process.
 A conceptual flowchart of the basic Event Loop.
A conceptual flowchart of the basic Event Loop.
This model immediately solves our lock problem. With a single thread of execution, there is no shared memory concurrency. You cannot have a race condition if there's only one runner in the race. No locks are needed.
But this raises a more profound technical question: How does getEvents() actually work? How can a server possibly know when a network packet has arrived on one of a thousand different connections?
select() and poll()
To implement an event loop, we need a mechanism to monitor multiple I/O sources simultaneously. We need to be able to say, "Hey, Operating System, I'm interested in these 1000 network sockets. Please put my process to sleep, and wake me up only when at least one of them has data ready to be read."
This is precisely what the select() and poll() system calls provide. They are the engine of the event loop. Let's examine select(), the classic API:
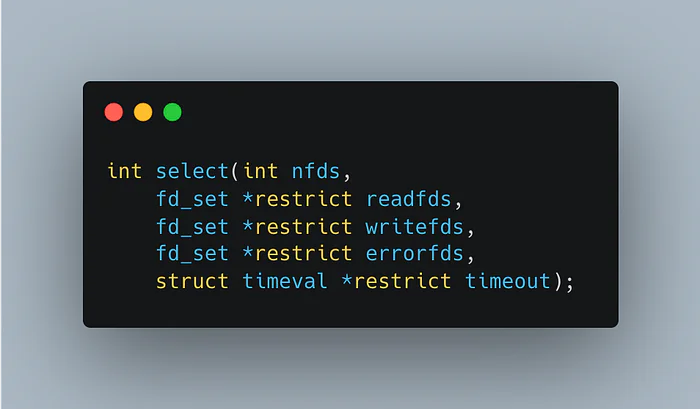
Don't be intimidated by the C declaration. The concept is straightforward:
You give select() three sets of file descriptors (which, in Unix, can represent network sockets, files, pipes, etc.).
readfds: The set you want to monitor for incoming data.
writefds: The set you want to monitor to see if it's okay to write to them (i.e., their outbound buffers aren't full).
errorfds: The set to monitor for exceptional conditions.
- You call select(). It blocks, putting your process to sleep.
- When data arrives on one of the sockets in readfds (or another condition is met), select() wakes your process up.
- Crucially, select() modifies the sets you passed in, leaving only the file descriptors that are actually "ready."
- Your event loop can now iterate through the modified sets to see which sockets need attention and call the appropriate event handlers.
Here is a sequence diagram illustrating this flow for a web server handling two clients.
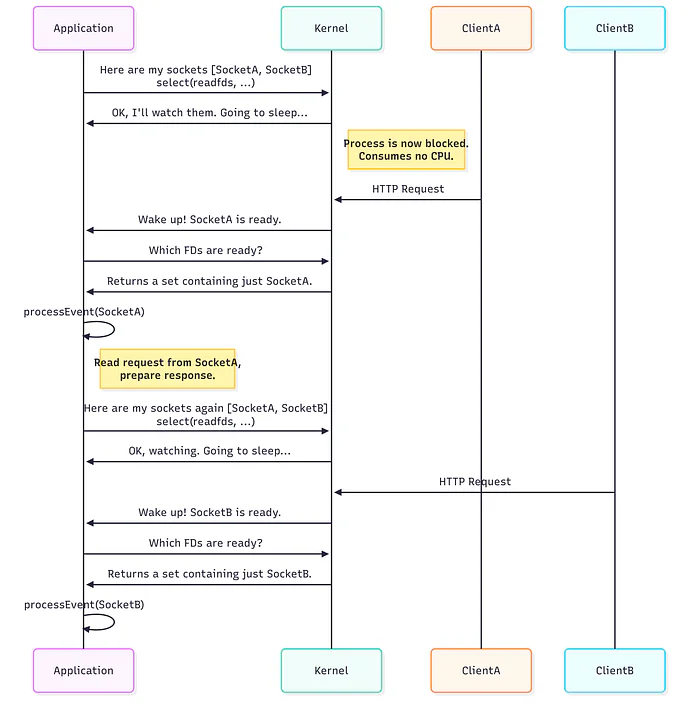
The select() system call acts as the gatekeeper, waking the application only when there is work to do.
With select(), we now have a non-blocking way to build our getEvents() function, allowing a single thread to efficiently manage thousands of concurrent connections.
The Blocking Call Catastrophe
We have built a beautiful, lock free, single threaded concurrent server. It hums along, processing network events with incredible efficiency. Then, a request comes in that requires reading a file from disk. Our event handler makes a standard read() system call.
The disk is slow. The read() call blocks.
And the entire server grinds to a halt. Hahahahah damn it.
Because there is only one thread, when it blocks waiting for the disk, nothing else can happen. No new connections can be accepted. No other network events can be processed. Thousands of clients are left waiting because one handler is stuck. This is the cardinal sin of event-based programming.
TIP: DON'T BLOCK IN EVENT BASED SERVERS
In an event based system, a single blocking call can halt all progress, destroying the very concurrency the model is meant to provide. To maintain control and responsiveness, no call that blocks the caller can ever be made. Every operation must be non-blocking.
But how can we possibly read from a disk or perform other long-running operations without blocking?
Asynchronous I/O (AIO)
The solution is to extend the non blocking philosophy from network I/O to all I/O. We need asynchronous I/O interfaces. Instead of saying, "Read this file and give me the data (I'll wait)," we need to be able to say, "Please start reading this file. Return to me immediately. Let me know later when you're done."
Modern operating systems provide exactly these kinds of APIs. A typical flow looks like this:
- Initiate: The application calls a function like aio_read(), passing it a control block. This structure contains all the information about the request: which file to read, where to put the data, how much to read, etc. This call returns immediately, allowing the event loop to continue.
- Poll/Notify: How do we know when the read is complete? There are two main approaches. Polling and Interrupts.
- Polling: The application can periodically call a function like aio_error() to check the status of the request. This can be integrated into the main event loop.
- Interrupts (Signals): A more advanced method is to have the OS deliver a UNIX signal to the application upon I/O completion, which triggers a special signal handler.
- Handle Completion: Once the application learns the I/O is complete, it can treat this completion as just another event and process the data.
This fundamental difference between synchronous and asynchronous I/O is the key to preserving the responsiveness of an event driven server.
 Asynchronous I/O is the antidote to the blocking call poison, allowing the event loop to remain active.
Asynchronous I/O is the antidote to the blocking call poison, allowing the event loop to remain active.
Manual Stack Management
This asynchronous power comes at a cost, and it is a cognitive one. Consider a simple task in a threaded program: read from a file, then write that data to a network socket.
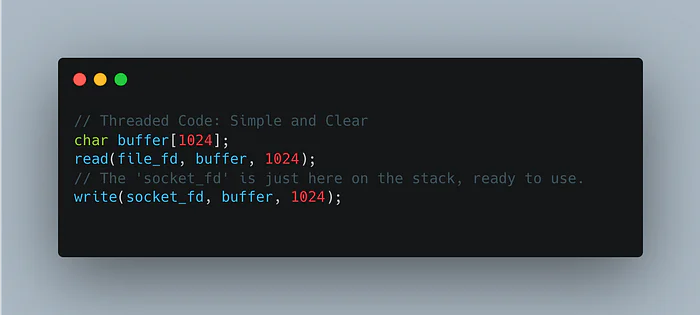
The state the socket_fd we need for the second step is implicitly saved on the thread's stack. When read() returns, the context is perfectly preserved.
Now consider the event-based equivalent.
- We issue an aio_read().
- Our event handler finishes, and the event loop goes on to process hundreds of other events.
- Much later, the I/O completion event arrives. Our new event handler fires.
But this new handler has a problem: How does it know which socket to write the data to? The original context, the socket_fd, is gone.
This is what researchers call manual stack management. In a threaded model, the stack is managed for you automatically. In an event based model, you have to do it yourself.
The solution is to create a continuation: a data structure that explicitly saves the state you'll need to continue the operation later.
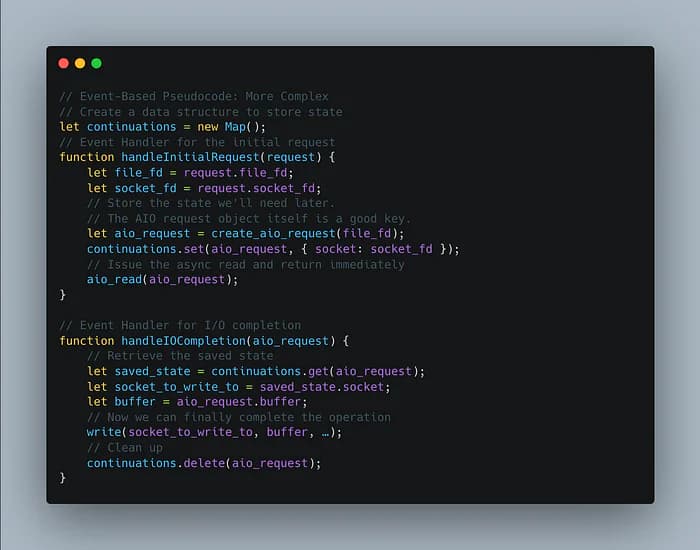
This explicit state management is the price of control. It makes the code more complex and harder to follow than its simple, linear, threaded counterpart. This is the fundamental trade-off of the event-based model.
Challenges in a Multi-Core World
The pure, single threaded, lock free model is beautiful, but the world has changed. We no longer live on single core machines. How does event based concurrency adapt?
- Utilizing Multiple Cores: To use multiple CPUs, you must run multiple processes, each with its own event loop. As soon as you do this and need them to share state (e.g., a cache), the familiar specter of synchronization returns. Locks are back on the table. Architectures like Node.js's "cluster" module or Nginx's worker process model are examples of this hybrid approach.
- Implicit Blocking: Even with perfect asynchronous I/O, your application can still block unexpectedly due to page faults (when memory is swapped to disk). An event handler might trigger a page fault, freezing the process until the page is loaded, once again stalling the entire server.
- API Fragmentation: Historically, asynchronous APIs for disk I/O and network I/O were separate and incompatible. You couldn't just put a disk descriptor into your select() call. Modern Linux interfaces like epoll and the revolutionary io_uring are working to unify these, but the ecosystem can still be complex to navigate.
A Powerful Pattern
Event based concurrency is not a silver bullet. It trades the implicit complexity of threads and schedulers for the explicit complexity of asynchronous logic and manual state management.
Despite its challenges, the event-based pattern has not only endured but thrived. It is the beating heart of Node.js, which brought event-driven programming to the masses. It is the secret to Nginx's ability to handle immense traffic with a tiny memory footprint. And its principles are now central to modern asynchronous frameworks in languages like Python (asyncio) and Rust (tokio).
By forcing us to think explicitly about state, I/O, and scheduling, the event-based model provides a level of control and a potential for performance that is difficult to achieve with threads alone. It is a testament to the fact that sometimes, the most powerful solutions in computer science are not the newest, but the ones that force us to be more deliberate, more disciplined, and more aware of what our code is truly doing. It is, in its own way, a hidden genius.